(acl 2020) Heterogeneous Graph Neural Networks for Extractive Document Summarization
概述
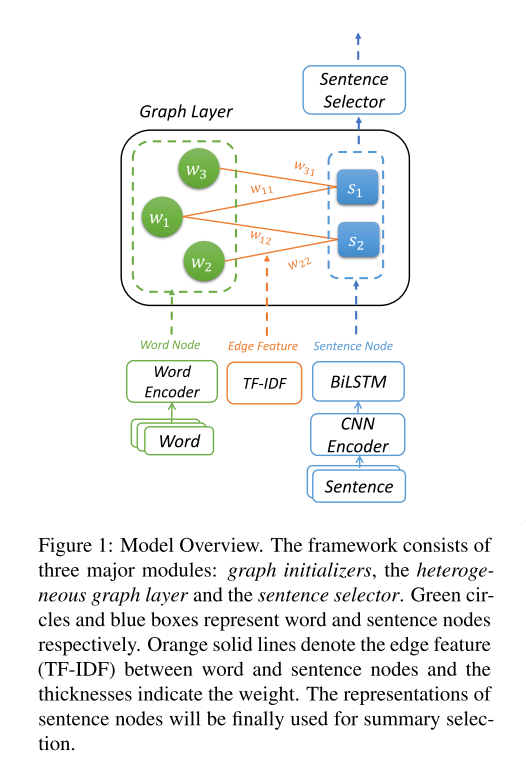
文章使用异质图建模句子之间的关系,并将其用于抽取式摘要,取得了优于所有对比模型的效果(本文模型和对比模型均没有使用预训练语言模型,如BERT)。
图的结构
- 图中包含两类节点:词节点和句节点
- 句节点与其中包含的词的节点相连接
- 只有词节点和句节点之间的连接,同类节点之间不会连接
- 是一个二分图(Bipartite Graph)
节点初始化
- 词节点
- 300维的Embedding
- Vocabulary大小为50000
- 使用GloVe初始化Embedding
- 删去停用词和标点符号
- 删去10%的在整个数据集上具有低TF-IDF的词语
- 句节点
- 128维向量
- 对句子先经过(从小到大不同kernel size的)CNN,再经过BiLSTM,最后连接CNN和BiLSTM的输出作为句节点向量
- 边
- 50维Embedding
- TF-IDF经L2归一化后乘9(box = 10)round到最近整数,即变换成0-9之一作为embedding index
节点间消息传递
\(GAT(H_Q, H_K, H_V)\): \(\begin{align} \text{Attention Score: } Z &= LeakyReLU(W_a[W_q H_{Q}; W_k H_K]) \\ \text{Attention Distribution: } \alpha_{ij} &= {exp(Z_{ij}) \over \sum_{l \in Neibor_i}{exp(Z_{il})}} \\ \text{Attention Vector: } u_i &= \sigma(\sum_{j \in Neibor_i}{\alpha_{ij} W_v H_V[j]}) \end{align}\)
- 使用Graph Attention(GAT)的方式进行消息传递
- 边的权重向量与query向量和key向量拼接在一起计算Attention Score
- 残差连接
- 多头注意力(8头×64维/头)
- 后跟Position-wise Feed Forward Layer:FFN
- 传递方式:sentence-to-word & word-to-sentence process,t = 1
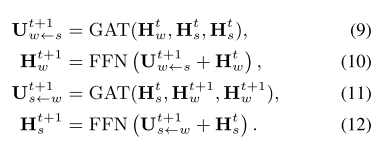
节点选择
- 句子节点特征向量被线性变换到一个出现在摘要中的概率
- 按照概率排序,选择前K个作为摘要
- Trigram Blocking:丢弃与排名较高的句子有重复三元组的句子
Implementation Note
- Use rouge (for validation phrase) and pyrouge to compute ROUGE easily
- Use sklearn to compute word frequency and TF-IDF matrix (
from sklearn.feature_extraction.text import CountVectorizer, TfidfTransformer) - GNN implemetation: DGL (also, H.Y. Lee ML TA recommend it)
- Use nltk to create Vocabulary (
nltk.FreqDist(allword)) , get sentences (nltk.sent_tokenize) and remove stopwords